Session 2
Introduction
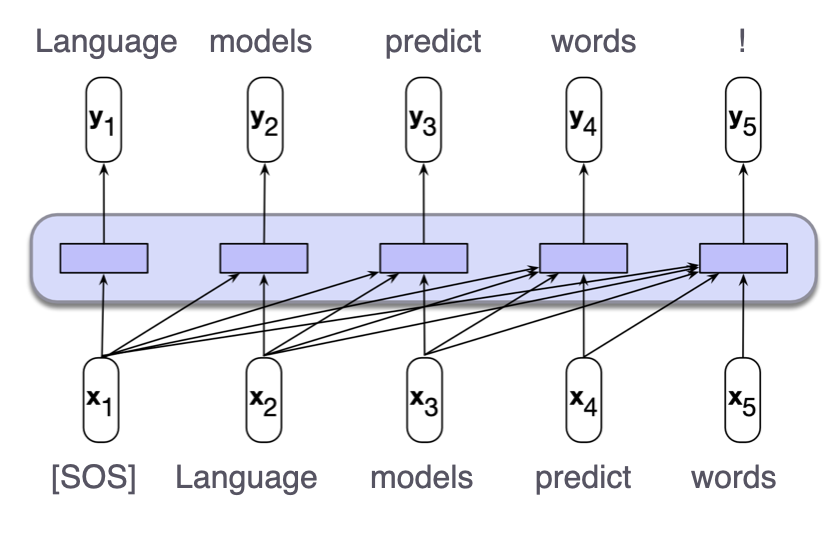
In this session, we provide an overview of the fundamental concepts behind core language models. That is, we take a look at training language models to predict the next word, also called pre-training – the step that is taken before pre-trained language models undergo further fine-tuning to become more helpful and harmless assistants (like, e.g., ChatGPT). By taking a tour over some technical details of language model mechanics and how they are evaluated in the literature, the main learning goals we are aiming for in this session are:
- understand what the core language modeling objective is (conceptually)
- understand the concepts behind different language model architectures
- understand the approach to evaluating trained language models.
That is, this session is meant to provide an overview of concepts crucial for a better understanding of more complex state-of-the-art systems and being able to discuss them based on a more solid conceptual background, rather then equip you with all details necessary for building core LMs from scratch.
Slides
Hands-on exercises
Below, you can find code for trying out pretrained models via the Huggingface library yourself. Additionally, there are snippets for looking at the effect of a critical moving part of LMs – the decoding scheme – in action.
Please find the Colab notebook containing code for the first two sections here.
Running the code
In order to explore, you don’t have to write a lot of code by yourself – you can use many handy functions provided by the library allowing you to download models, tokenize text (i.e., map natural language (sub)words to numbers which a machine can use for computations), sample predictions of the pretrained models. To try different decoding schemes, you will only have to take a look at the different parameters of the generation functions. So even if you have never written code for using LLMs before we encourage you to take on the challenge and try running the code and doing the exercises below.
We strongly encourage you to use the Colab notebook provided above (Colab is a Jupyter server hosted by Google), run the provided code and paste the additional code below into it. The only requirement fot that is a Google account. You can find instructions on how to use Colab notebooks here.
If you are a more advanced programmer and really want to run the code locally on your machine, we strongly encourage you to create an environment (e.g., with Conda) before you install any dependencies, and please keep in mind that pretrained language model weights might take up quite a bit of space on your hard drive or might require high RAM for prediction.
Generating predictions from models
The notebook contains code for loading the pretrained GPT-2 model and generating some sentence completions with it. The notebook already contains some exercises; if you’d like to challenge yourself a bit more, you can also think about the following exercises.
Exercise
Besides core language models which generate text continuations (i.e., simply predict next tokens), Huggingface offers a variety of models fine-tuned for different other tasks. These often come with different model heads.
- Create a few example inputs for GPT-2 in a different language than English. Does the quality of the prediction intuitively match the quality of English predictions?
- Load a version of BERT fine-tuned for question answering by adapting the code above (the Huggingface model ID is ‘deepset/bert-base-cased-squad2’) and create or find three examples of contexts and questions which could be answered based on information in context. What does the task-specific head for this model do?
Comparing decoding schemes
One import aspect which determines the quality of the text produced by language models is the decoding strategy. The notebook shows how to use several popular decoding schemes with GPT-2. Of course, they can also be applied to other generative language models.
Loading evaluations
In the lecture we discussed different metrics and benchmarks for evaluating language models. Below you can find the code for loading a Wikipedia-based test dataset frequently used to compute the test performance of models. Please paste the code below into the Colab notebook in order to try it out.
Exercise
The code below provides the negative log likelihood of the first 50 tokens in the dataset under GPT-2. Based on the NLL, compute the perplexity of this sequence under GPT-2.
# import Huggingface package managing open source datasets
from datasets import load_dataset
import numpy as np
test = load_dataset("wikitext", 'wikitext-2-raw-v1', split="test")
encodings = tokenizer(
"\n\n".join(test["text"]),
return_tensors="pt",
).input_ids
input_tokens = encodings[:,10:50]
pretty_print(input_tokens[0])
output = model(input_tokens, labels = input_tokens)
print("Average NLL for wikipedia chunk", output.loss.item())
### your code for computing the perplexity goes here ###
# perplexity =
When evaluating generated text for tasks like translation or summarization, metrics like BLEU-n are employed. We will use the T5 model which was also trained to translate between English, German and French. The snippet below is based on this tutorial.
Exercise
- Use the code below to compute the BLEU score for the provided English sentence into German based on the prediction by the model and the provided gold standard.
- Try to paraphrase the gold standard translated sentence slightly and compute the BLEU score again. What happens to the score and why?
- Find some additional examples of translations between different languages here or come up with some examples sentences yourself (e.g., a sentence in your native language and its English translation).
# import the implementation of the bleu score computation
from torchtext.data.metrics import bleu_score
# load model and tokenizer
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
tokenizer_t5 = T5Tokenizer.from_pretrained("t5-small")
model_t5 = T5ForConditionalGeneration.from_pretrained("t5-small")
# define example sentences for translating from English to German
text_en = "All of the others were of a different opinion."
text_de = "Alle anderen waren anderer Meinung."
# define task
prefix = "translate English to German: "
# define helper function taking prediction and gold standard
def compute_bleu(prediction, target, n):
"""
Parameters:
----------
prediction: str
Predicted translation.
target: str
Gold standard translation.
n: int
n-gram over which to compute BLEU.
Returns:
-------
score: float
BLEU-n score.
"""
score = bleu_score(
[prediction.split()],
[[target.split()]],
max_n=n,
weights = [1/n] * n,
)
return score
# encode the source and the target sentences
encoding_en = tokenizer_t5(
[prefix + text_en],
return_tensors="pt",
).input_ids
# we don't need the task prefix before the target
encoding_de = tokenizer_t5(
[text_de],
return_tensors="pt",
).input_ids
# predict with model
predicted_de = model_t5.generate(encoding_en)
print("Predicted translation: ", predicted_decoded_de)
# decode the prediction
predicted_decoded_de = tokenizer_t5.decode(
predicted_de[0],
skip_special_tokens=True,
)
# compute BLEU-1 for the prediction
### YOUR CODE CALLING THE HELPER ABOVE GOES HERE ###
# bleu1 =