Session 3
Introduction
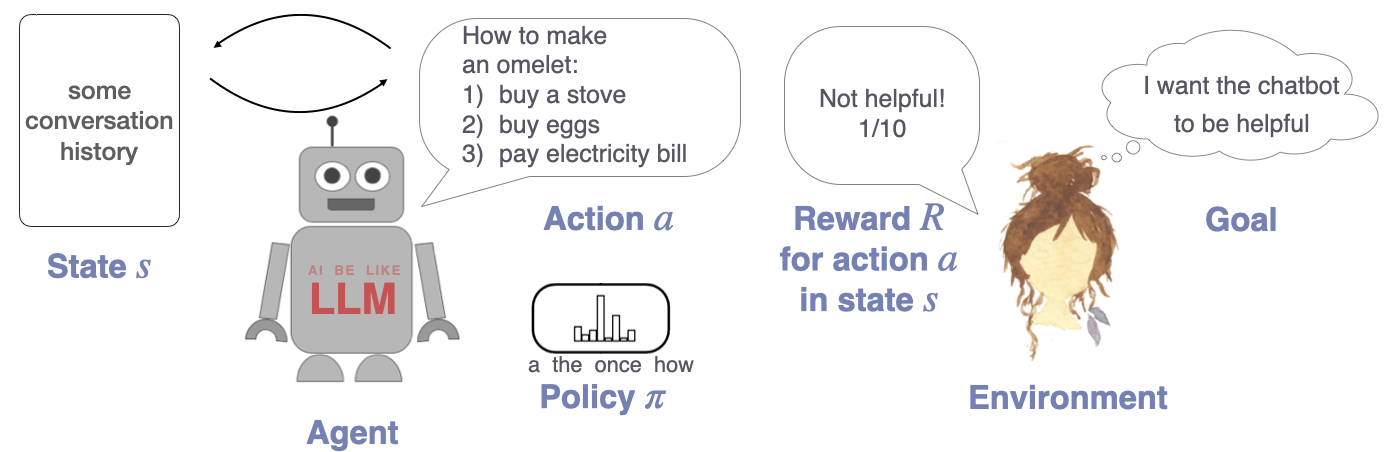
In this session, we will take a look at the core technology used to convert LLMs pretrained on plain language modeling into maximally helpful, flexible and interactive assistants — Reinforcement Learning from Human Feedback (RLHF). The core idea of this approach is to adapt the models so that they satisfy human preferences. More specifically, they are trained on human feedback which formalizes goals (e.g., being helpful, honest, harmless) by rewarding model outputs which satisfy these goals, and dispreferring those that don’t. The computational framework that allows to implement such learning and actually train a neural network is reinforcement learning (RL).
The field of reinforcement learning (which is often considered a type of machine learning, next to supervised an unsupervised learning) has a long history and initially focused on optimal control in the 1950s. After some years of stagnation, it became increasingly popular in the 1980s and gained public awareness after 2015 when DeepMind used RL to create the famous AlphaZero. Now, RLHF (a specific instantiation of a deep RL based optimization procedure) is attracting increasing attention with the release of GPT-3.5 and GPT-4, as their naturalness and capacities might partly be due to this technology.
This session focuses on the core conceptual aspects of RLHF and omits theoretical aspects of RL which are irrelevant to the pipelines currently employed for training LLMs. In case you are curious about RL more boradly, you can find some useful resources here. After introducing RLHF, the lecture contains a quick tour over currently popular LLMs and dives into practically relevant aspects, namely, creating effective prompts for the models. Therefore, the learning goals for this session are:
- being able to identify purpose and motivation behind fine-tuning LLMs with RLHF
- understanding basics of RLHF and the following building blocks:
- fine-tuning
- reward model
- PPO
- becoming familiar with recent LLMs
- being able to use sophisticated prompting to control LLM output
Equipped with a conceptual understanding of how LLMs are built, we will already touch upon important topics like alignment, truthfulness and interpretability.
Slides
Links to materials mentioned in this session can be found here.
Code
Python script from the lecture for GPT-2 and FLAN T5 generations.
Additional resources on RL
These resources are a short suggested selection among infinitely many (possibly better, except for the textbook) further resources out there:
- intuitive video about RLHF
- series of great videos about deep RL in general by one of the most well-known researchers in the field, Pieter Abbeel
- OpenAI blogpost about PPO
- an intuitive video about PPO, but it presupposes some general knowledge of RL
- the textbook about RL (detailed and in-depth)
- high-level blogpost about the development of the field
Web-book on prompt engineering
Further materials used in the session
Below are links to papers which were referenced in the lecture but weren’t linked to: