Homework 2: Fine-tuning & Prompting of LMs (51 points)#
The focus of this homework is on one prominent fine-tuning technique – reinforcement learning from human feedback – and on critically thinking about prompting techniques and papers about language models
Logistics#
submission deadline: June 3rd th 23:59 German time via Moodle
please upload a SINGLE .IPYNB FILE named Surname_FirstName_HW2.ipynb containing your solutions of the homework.
please solve and submit the homework individually!
if you use Colab, to speed up the execution of the code on Colab, you can use the available GPU (if Colab resources allow). For that, before executing your code, navigate to Runtime > Change runtime type > GPU > Save.
Exercise 1: Advanced prompting strategies (16 points)#
The lecture discussed various sophisticated ways of prompting language models for generating texts. Please answer the following questions about prompting techniques in context of different models, and write down your answers, briefly explaining them (max. 3 sentences). Feel free to actually try out some of the prompting strategies to play around with them and build your intuitions.
Consider the following language models:
GPT-4, Qwen-2.5-Coder-32B, Mistral-24B-Instruct, Llama-2-70b-base.
Consider the following prompting / generation strategies:
tree-of-thought reasoning, zero-shot chain-of-thought prompting, few-shot prompting, self-reflection prompting.
For each model:
which strategies do you think work well, and why?
For each prompting strategy:
Name an example task or context, and model, in which you would think they work best. Briefly justify why.
Exercise 2: RLHF for summarization (15 points)#
In this exercise, we want to fine-tune GPT-2 to generate human-like news summaries, following a procedure that is very similar to the example of the movie review generation from sheet 4.1. The exercise is based on the paper by Ziegler et al. (2020).
To this end, we will use the following components:
in order to initialize the policy, we use GPT-2 that was already fine-tuned for summarization, i.e., our SFT model is this
as our reward model, we will use a task-specific reward signal, namely, the ROUGE score that evaluates a summary generated by a model against a human “gold standard” summary.
a dataset of CNN news texts and human-written summaries (for computing the rewards) for the fine-tuning which can be found here. Please note that we will use the validation split because we only want to run short fine-tuning.
NOTE: for building the datset and downloading the pretrained model, ~4GB of space will be used.
YOUR TASK:
Your job for this task is to set up the GRPO-based training with the package
trl, i.e., the set up step 3 of this figure. GRPO (Group Relative Policy Optimization) is an RL algorithm that was proposed by Shao et al. (2024) for the DeepSeek math model.
Please complete the code or insert comments what a particular line of code does below where the comments says “#### YOUR CODE / COMMENT HERE ####”. For this and for answering the questions, you might need to dig a bit deeper into the working of GRPO, the algorithm that we are using for training. You can find relevant information on the implementation, e.g., here.
To test your implementation, you can run the training for ~250 steps, but you are NOT required to train the full model since it will take too long. We will NOT be evaluating your submission based on the performance of the model.
Answer the questions below.
{kind=link}
# !pip install gcsfs==2025.3.0 fsspec==2025.3.0 accelerate==1.6.0 trl==0.17.0 evaluate rouge_score datasets
# import libraries
import torch
from tqdm import tqdm
import pandas as pd
tqdm.pandas()
from transformers import AutoTokenizer
from datasets import load_dataset
from trl import (
GRPOTrainer,
GRPOConfig,
)
import evaluate
#### YOUR COMMENT HERE (what is the purpose of this code?) ####
config = GRPOConfig(
#### YOUR COMMENT HERE (what is the meaning of each of the following parameters?) #####
learning_rate=1.41e-5,
#### YOUR COMMENT HERE ####
max_steps=250,
#### YOUR COMMENT HERE ####
per_device_train_batch_size=8,
#### YOUR COMMENT HERE####
num_generations=8,
#### YOUR CODE HERE: set the number of overall training epochs to 1 ####
,
#### YOUR COMMENT HERE####
logging_steps=1,
#### YOUR COMMENT HERE####
report_to="none",
)
We load the CNN dataset and truncate the texts to 512 tokens, because we don’t want the training to be too memory heavy and we want to have “available” some tokens for the generation (GPT-2’s context window size is 1024). Then we tokenize each text and pad it.
def build_dataset(
model_name,
dataset_name="abisee/cnn_dailymail"
):
"""
Build dataset for training. This builds the dataset from `load_dataset`.
Args:
model_name (`str`):
The name of the SFT model to be used, so that the matchin tokenizer can be loaded.
dataset_name (`str`):
The name of the dataset to be loaded.
Returns:
dataloader (`torch.utils.data.DataLoader`):
The dataloader for the dataset.
"""
tokenizer = AutoTokenizer.from_pretrained(#### YOUR CODE HERE ####)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'left'
# load the datasets
ds = load_dataset(dataset_name, '1.0.0', split="validation")
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(
#### YOUR CODE HERE (hint: inspect the dataset to see how to access the input text)####,
return_tensors="pt",
max_length=512,
truncation=True,
padding="max_length"
)
# get the truncated natural language text, too
sample["prompt"] = #### YOUR CODE HERE ####
sample["ground_truth"] = #### YOUR CODE HERE ####
return sample
ds = ds.map(tokenize, batched=False)
ds.set_format(type="torch")
return ds
# use tokenizer from HF named: "gavin124/gpt2-finetuned-cnn-summarization-v2"
# build the dataset
dataset = #### YOUR CODE HERE ####
def collator(data):
return dict((key, [d[key] for d in data]) for key in data[0])
# inspect a sample of the dataset
print(dataset[0])
We load the tokenizer corresponsing to the SFT GPT2 model that we already used above to pretokenize the dataset.
tokenizer = AutoTokenizer.from_pretrained(#### YOUR CODE HERE ####)
tokenizer.padding_side='left'
tokenizer.pad_token = tokenizer.eos_token
Below, we define our custom reward function:
rouge = evaluate.load("rouge")
def reward_fn(
output: list[str],
original_summary: list[str]
):
"""
#### YOUR COMMENT HERE ####
"""
scores = []
for o, s in list(zip(output, original_summary)):
score = rouge.compute(predictions=[o.strip()], references=[s])["rouge1"]
scores.append(torch.tensor(score))
return scores
Nest, we set up the trainer:
#### YOUR COMMENTS BELOW (what are the congle lines doing?) ####
grpo_trainer = GRPOTrainer(
args=config,
model="gavin124/gpt2-finetuned-cnn-summarization-v2",
reward_funcs=reward_fn,
processing_class=tokenizer,
train_dataset=dataset,
)
#### YOUR CODE HERE: plot the loss and the rewards of the model training by accessing the trainer logs under grpo_trainer.state.log_history ####
#### YOUR COMMENT HERE: do the plots indicate a trend towards successful training? ####
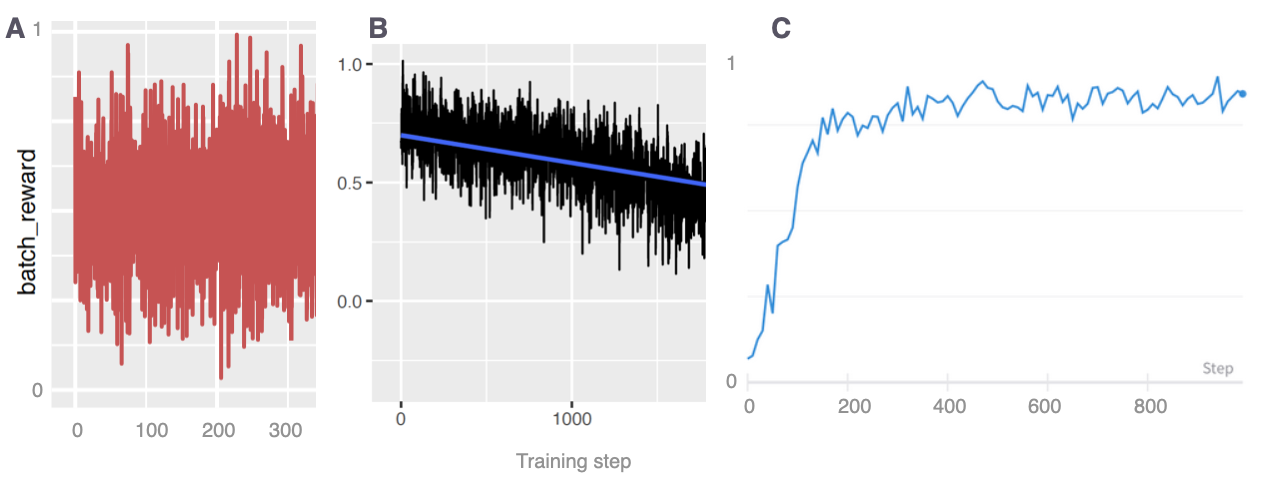
QUESTIONS:
Suppose the plots of rewards below show training metrics for different runs of the summarization model training. Interpret what each of the plots tells us about training success; i.e., did the training run go well on this run? Do we expect to get good summaries? Why? Be concise!
We have truncated the query articles to maximally 512 tokens. Given that we are using ROUGE with respect to ground truth summaries as a reward, why might this be problematic?
GRPO is an algorithm improving over the PPO algorithm (Proximal Policy Optimization). What is they aspect that helps improve over PPO? Explain briefly.
In the GRPO paper referenced above, on page 14, you can find the pseudo-algorithm for GRPO. For lines 1–4, 7–8 of the pseudo-code, write down what in our code above instatiates the concepts in the pseudo-code.
In your own words, explain intuititvely what the role of the group in the algorithm is and why it is used. Use max. 3 sentences.
Name the parameter in the code above that determines the group size.
Exercise 3: First neural LM (20 points)#
Next to reading and understanding package documentations, a key skill for NLP researchers and practitioners is reading and critically assessing NLP literature. The density, but also the style of NLP literature has undergone a significant shift in the recent years with increasing acceleration of progress. Your task in this exercise is to read a paper about one of the first successful neural langauge models, understand its key architectural components and compare how these key components have evolved in modern systems that were discussed in the lecture.
Specifically, please read the paper by Bengio et al. (2003) and answer the following questions:
How were words / tokens represented? What is the difference / similarity to modern LLMs?
How was the context represented? What is the difference / similarity to modern LLMs?
What is the curse of dimensionality? Give a concrete example in the context of language modeling.
Which training data was used? What is the difference / similarity to modern LLMs?
Which components of the Bengio et al. (2003) model (if any) can be found in modern LMs?
Furthermore, your task is to carefully dissect the paper by Bengio et al. (2003) and analyse its structure and style in comparison to another more recent paper: Devlin et al. (2019) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
TASK:
For each section of the Bengio et al. (2003) paper, what are key differences between the way it is written, the included contents, to the BERT paper (Devlin et al., 2019)? What are key similarities? Write max. 2 sentences per section.